

When building software, it’s quite usual for a company to have more than one environment to deploy to. Depending on how many there are, managing these environments and their respective branches in source control can become tricky. In one of the more basic scenarios, we might have one internal staging environment for deploying a test build onto. Once QA have done their magic and given it the green light, that build could then be deployed to production for the next release. In this setup, there are two branches corresponding to each of the environments: staging, and production.
I once worked at a company where there were four.
In order of being least ready for production, these were:
CI: used for continuous integration and unit testing.Staging: used for internal testing, primarily by QA.Preproduction: used for internal testing, mostly by product management.Production: used by customers.
During each sprint, we would work on local feature branches on our own development machines. When a feature was ready, its respective branch would be merged into CI. This triggered an automated process where unit tests ran against the updated code. If successful, binaries were created and deployed, and integration tests were run against the updated system.
In an ideal situation, no bugs would be found by the end of a two-week Sprint cycle; each environment’s binaries would be promoted to the next level up and deployed:
Productionwould be replaced byPreproductionduring a release window.Stagingwould replacePreproductionshortly after.CIwould replaceStagingshortly after that.
Where feasible, we kept binaries from the original CI builds and redeployed them during the environment promotions. This would happen all the way up to production. Using artefacts created during previous lifecycle stages was important: it meant that we could rule out code changes and modifications to the build pipeline if anything went wrong or was different after being deployed to a new environment. Other factors might include deployment variables and system configuration, but we knew that it wouldn’t be the binary itself; it had already been previously deployed and verified elsewhere.
Despite using builds from CI to deploy all the way to production, we kept branches in Git for each environment. When an environment was promoted, its corresponding branch would be merged into the branch for the environment that it was going to. This made sure that the code was in sync, even if we wouldn’t necessarily be building a binary from that branch.
Under this system, having two-week Sprint cycles meant it took between four and six weeks for fresh code to make it to production. This was fine for new features and enhancements.
But what about bugs found on staging? And how did we prevent issues found on preproduction from being released?
Hot fixes and patches needed to be fast-tracked; the otherwise minimum of four weeks would have been too long. At a high level we would:
Check out the code for the affected branch.
Make any necessary changes.
Prevent regressions by merging those changes into the branches of ‘lower’ environments (i.e. towards
CI, rather thanProduction).
Patching Environments
To examine the process in more detail, let’s look at the example of fixing a bug found in preproduction. The first step would be to check out the branch for Preproduction. Image 1 shows a simplified repository in Git Extensions. Note that work has already started on Feature 2 on the CI branch.
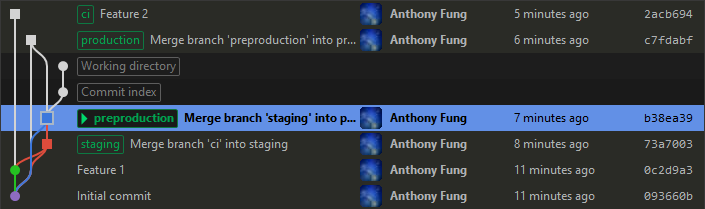
Image 1: The Preproduction branch has been checked out
Image 2 shows how the repository would look like after committing a fix for the bug. The Preproduction branch would then be built, tagged in Git with the build number, and deployed for testing and verification. Once confirmed as fixed, this (updated) build would be deployed to production during the following release window.
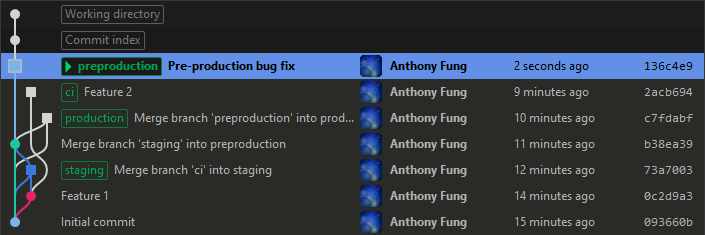
Image 2: A fix for the Preproduction bug has been committed
Finally, we wanted to make sure that a regression didn’t occur when the preproduction build was eventually replaced with the staging build. To do this, we merged Preproduction back into Staging. Staging was subsequently merged into CI.
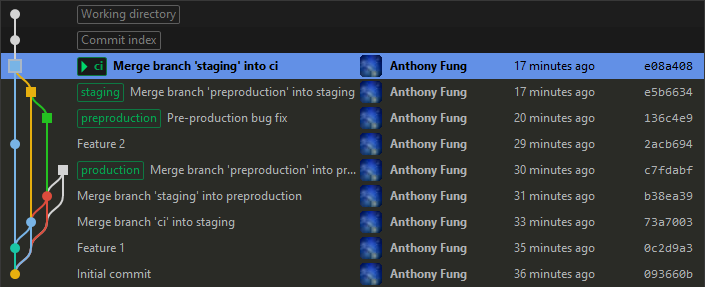
Image 3: The fix has been merged into Staging and CI to prevent a regression
Image 3 shows the repository after the bug fix has been merged into Staging and CI. As we can see, adding the fix to the CI branch didn’t affect the work on Feature 2.
Wrapping Up
This was one example of how the team I was in managed code for multiple environments. By following this strategy, we were able to stop known bugs from being experienced by customers and/or corrupting user data.
One important aspect was that binaries built earlier on in the release lifecycle were (re)deployed at later stages. This allows you to rule out code changes and build pipeline modifications if any behaviours are unexpected after deployment to a new environment.
If any bugs are fixed after an initial build from the continuous integration branch, it’s important to merge them to environments in the direction away from production. This will prevent regressions of those issues from happening after an environment promotion.
The release lifecycle for each system should be different and tailored for its project. However, they should all allow bugs to be caught before they go live. Working with this system taught me something about how to manage multiple internal testing environments. If you ever need to design your own, I hope you’ll find some of these insights useful too.